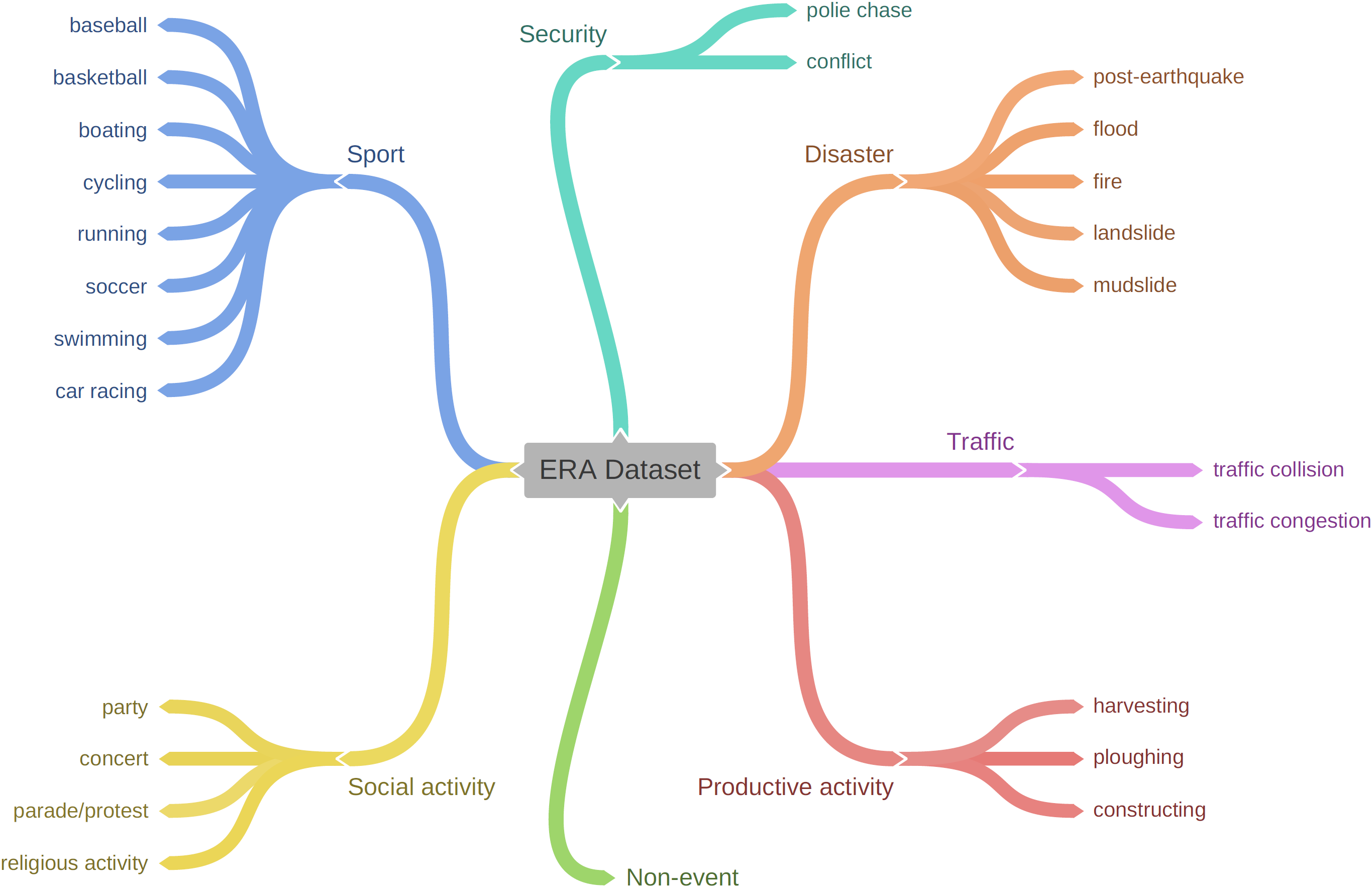
Statistics
The goal of this work is to collect a large, diverse dataset for training models for event understanding in UAV videos. As we gather aerial videos from Youtube, the largest video sharing platform in the world, we are capable of including a large breadth of diversity that would be more challenging than making use of self-collected data. In total, we have gathered and annotated 2,864 videos for 25 classes. Each video sequence is at 24 fps (frames per second), in 5 seconds, and with a spatial size of 640×640 pixels.